
“Dalam era digital yang begitu kompetitif ini, bisnis yang sukses adalah mereka yang tidak hanya mampu menarik pelanggan baru, tetapi juga mempertahankan kesetiaan pelanggan yang sudah ada. Dalam upaya memperkuat hubungan dengan pelanggan dan meningkatkan retensi, prediksi churn memiliki peran yang sangat vital. Dalam artikel ini, akan dijelajahi bagaimana implementasi analisis data yang akurat dan cerdas dapat menghasilkan wawasan mendalam, membantu bisnis mengidentifikasi pelanggan yang berpotensi meninggalkan layanan, dan akhirnya mengoptimalkan kinerja bisnis dengan mempertahankan loyalitas pelanggan secara efektif.”
Pelanggan dapat diprediksi churn atau tidak tentunya memiliki beberapa paramater dan penanganan yang khusus terlebih dahulu yang terbagi menjadi beberapa sebagai berikut:
1. Business Understanding
2. Data Understanding
3. Data Cleaning & EDA (Exploratory Data Analysis)
4. Data Preprocessing
5. Data Modelling
6. Evaluation Model
7. Conclusion
Dari tahapan-tahapan ini langkah ke-1 hingga langkah ke-3 sudah dilakukan pada project data analyst yang terkait dengan ini, lebih detailnya bisa dicek pada link berikut: https://jagoketik.com/blog/langkah-demi-langkah-mengeksplorasi-keputusan-bisnis-melalui-proyek-data-analyst/
Selanjutnya akan dimulai dari langkah ke 4 yaitu Data Preprocessing.
4. Data Preprocessing
Data Preprocessing adalah salah satu langkah penting sebelum melakukan modelling machine learning. Proses ini dilakukan setelah data bersih dan diketahui insight yang didapat dari data tersebut sehingga nantinya penanganan-penanganan yang tepat dapat terpenuhi agar hasil akurasi dari model machine learning untuk memprediksi pelanggan churn bisa lebih akurat. Hal pertama yang dilakukan dalam data preprocessing adalah melakukan transformasi data.
4.1 Transformasi Data
Transformasi data diperlukan karena merupakan salah satu paramater yang berperan penting dalam akurasi model machine learning. Sebelumnya cek terlebih dahulu data yang sudah dibersihkan dan dilakukan EDA, berikut adalah datanya.
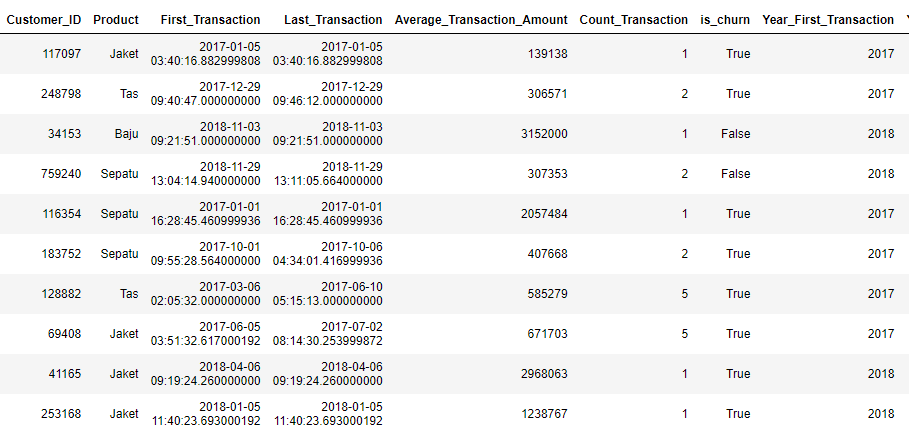
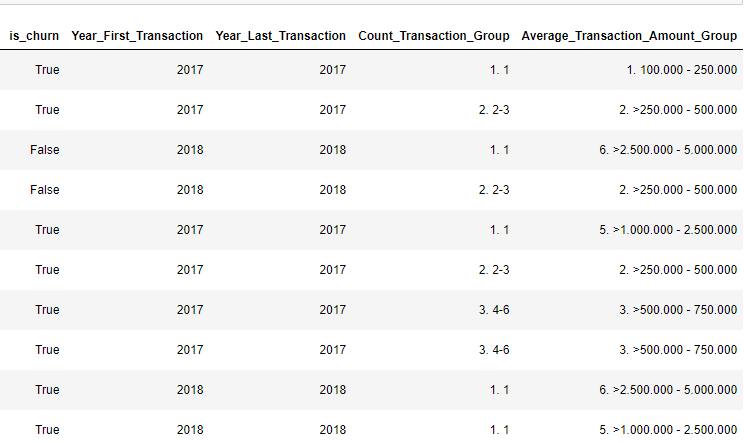
Dari sini terlihat ada beberapa kolom yang harus dilakukan transformasi seperti is_churn yang berisi True dan False, karena machine learning hanya menerima output berupa angka maka perlu dilakukan penanganan dengan cara mengubahnya menjadi angka dengan ketentuan True bernilai 1 dan False bernilai 0. Setelah dilakukan transformasi maka hasilnya akan seperti berikut.
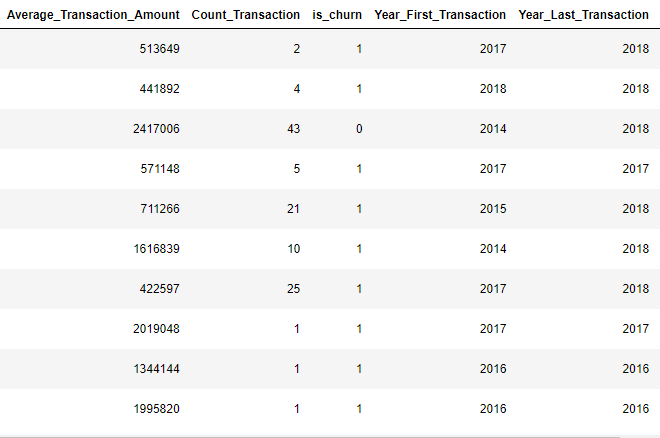
Setelah itu ada beberapa kolom yang tidak terpakai, namun bisa ditransformasi menjadi lebih efisien seperti kolom Year_First_Transaction dan Year_Last_Transaction menjadi selisih tahun antara transaksi pertama dan terakhir pelanggan yang akan didefinisikan menjadi Year_diff, akan tampak hasilnya sebagai berikut.
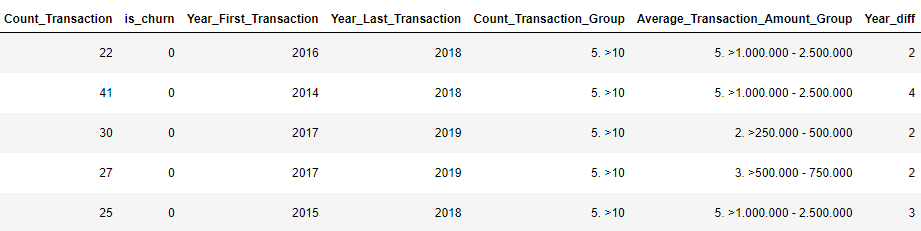
4.2 Korelasi antar data
Selanjutnya adalah mencari tahu bentuk korelasi antar data, penting mengetahui hal ini karena jika tidak ada korelasi antar data bisa jadi model yang dihasilkan juga kurang akurat dan memungkinkan model kesulitan dalam memahami pola dari data, berikut adalah korelasi antar variabel(kolom).
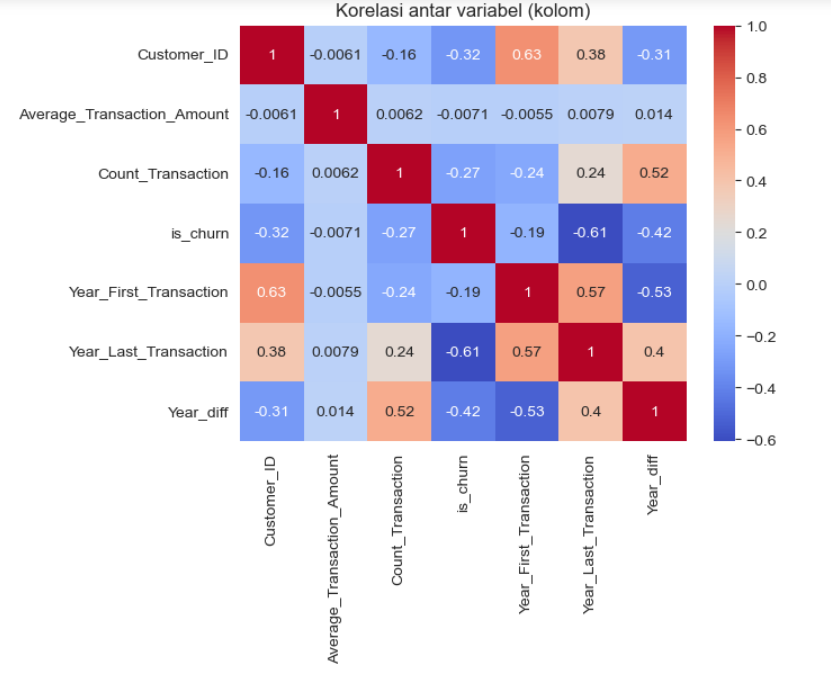
Pada gambar di atas terlihat is_churn sebagai target memiliki korelasi terhadap Average_Transaction_Amount, Count_Transaction, dan Year_diff. Sebenarnya juga ada korelasinya dengan Customer_ID namun kolom ini memiliki data yang unik sehingga tidak cocok jika digunakan sebagai predictor(selanjutnya disebut fitur). Begitu juga dengan kolom Year_First_Transaction dan Year_Last_Transaction sebenearnya memiliki korelasi namun dapat diwakilkan oleh Year_diff, di sisi selain kedua kolom tersebut memiliki korelasi yang lumayan kuat takutnya akan terjadi Multikolinearitas, Redundansi Informasi dan Overfitting jika ada dua atau lebih fitur yang memiliki korelasi yang kuat.
4.3 Pemilihan fitur dan label/target
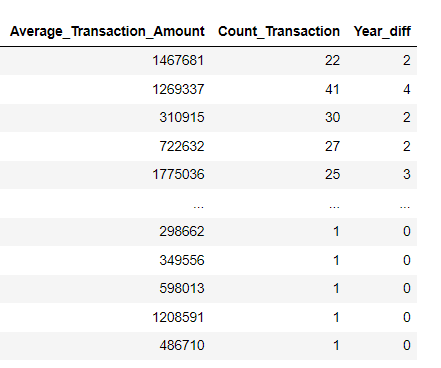
Selanjutnya dalam pembuatan model machine learning perlu dipisahkan terlebih dahulu mana kolom-kolom yang akan bertindak sebagai variabel independent atau fitur dan mana kolom yang digunakan sebagai variabel dependent atau label/target. Pada langkah 4.2 diketahui akhirnya ada 3 kolom yang akan bertindak sebagai fitur yaitu Average_Transaction_Amount, Count_Transaction, dan Year_diff, lalu is_churn sebagai label/targetnya.

4.4 Pemisahan data latih dan data uji
Selanjutnya adalah membagi dataset menjadi data latih/train(selanjutnya disebut data train) dan data uji/test(selanjutnya disebut data test), hal ini dilakukan karena data train akan digunakan untuk melatih model mengenali pola-pola dari data, lalu data test adalah data yang dianggap data baru sehingga bisa digunakan untuk menguji keakurasian model yang digunakan, digunakan pembagian sebanyak 80:20 artinya 80% data train dan 20% data test, berikut adalah hasil dataset setelah dipisahkan.

Terlihat sebelumnya pada fitur(di definisikan sebagai X) awalnya memiliki baris sebanyak 100.000 dan setelah dibagi akan menghasilkan jumlah data_train sebanyak 80.000(80%) dan data_test sebanyak 20.000(20%). Begitu pula pada target/label(di definisikan sebagai y) juga mengalami hal yang serupa.
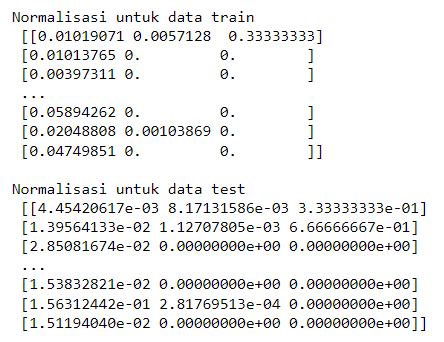
4.5 Normalisasi data
Jika dilihat pada langkah 4.3 terlihat nilai-nilai antara Average_Transaction_Amount, Count_Transaction, dan Year_diff tidaklah merata, di mana nilai Average_Transaction_Amount sangat jauh jika dibandingkan fitur lainnya maka dari itu perlu dilakukan penanganan untuk hal ini. Metode yang digunakan untuk hal ini adalah Min Max Scaler, metode ini mampu mengubah fitur-fitur data ke dalam rentang tertentu (biasanya antara 0 dan 1) dengan menjaga bentuk distribusi relatif dan relasi antar nilai. Proses normalisasi ini dapat membantu meningkatkan performa beberapa algoritma machine learning. Berikut adalah nilai-nilai dari fitur yang telah dinormalisasi dengan maksimal nilainya adalah 1 dan minimal adalah 0.
5. Data Modelling
Pada tahap ini akan diuji beberapa model supervised classification machine learning terhadap data yang telah disiapkan untuk memprediksi pelanggan churn. Adapun beberapa model yang dipilih adalah sebagai berikut.
1. Logistic Regression
2. Decision Tree Classifier
3. Random Forest Classifier
4. K-Nearest Neighbor Classifier
5. Naive Bayes
6. Gradient Boosting Classifier
7. Neural Network
8. Ada Boost Classifier
9. XGBoost Classifier
Setelah ditentukan model machine learning apa saja yang akan digunakan pada data, berikut adalah hasil masing-masing dari model.
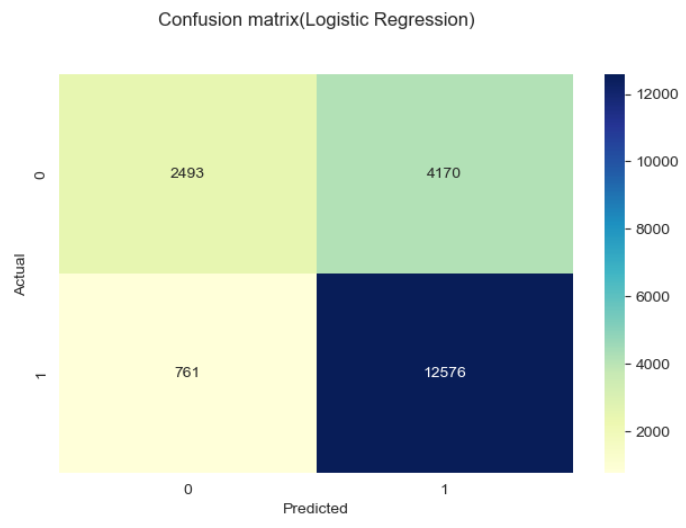
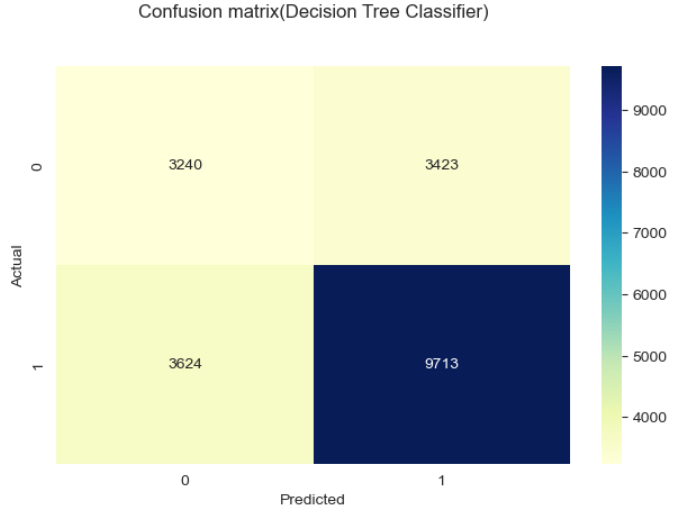
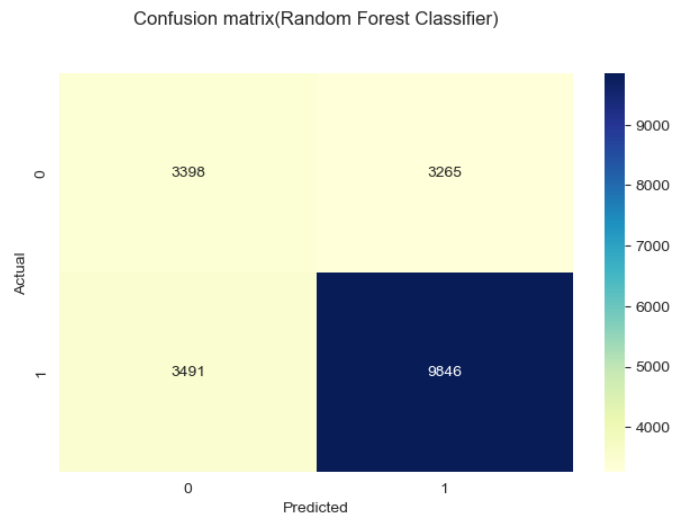
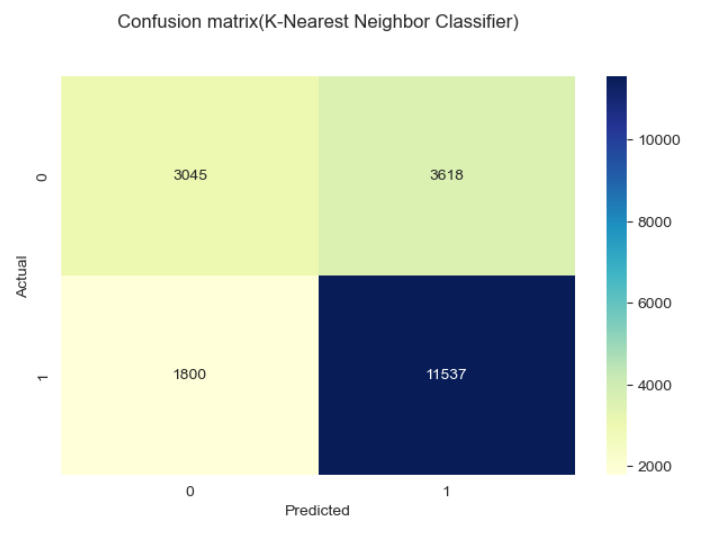
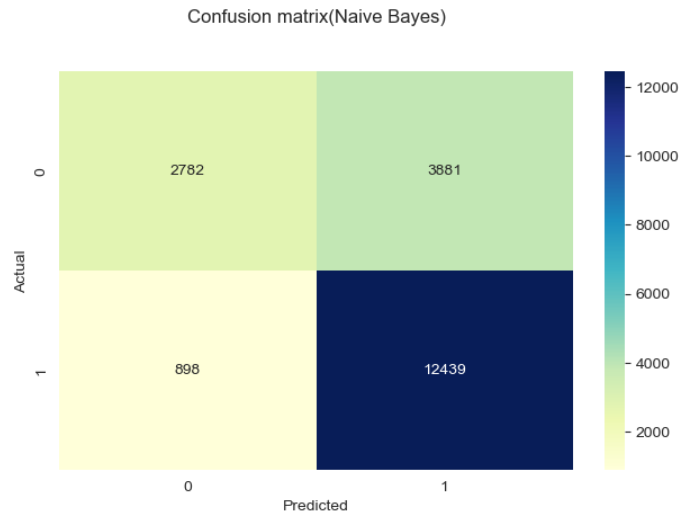
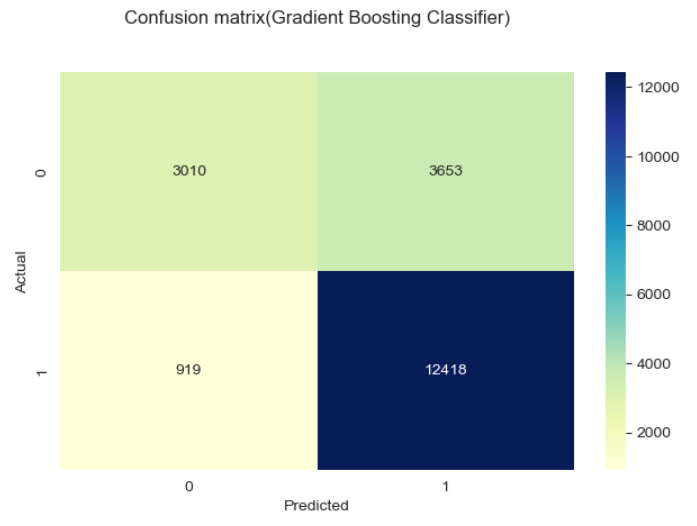
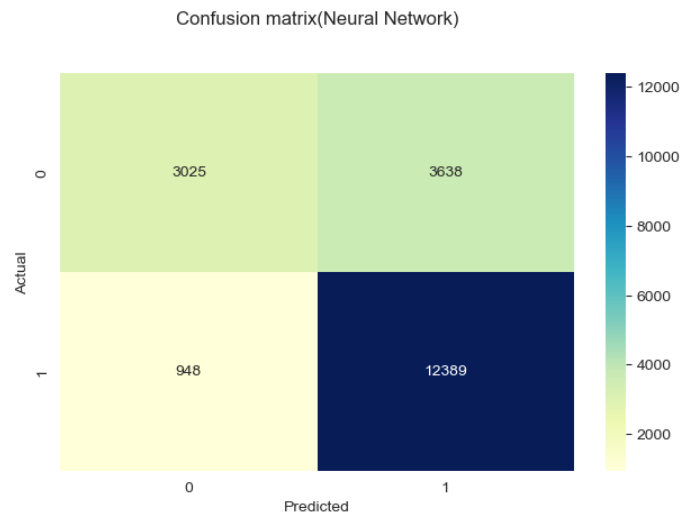
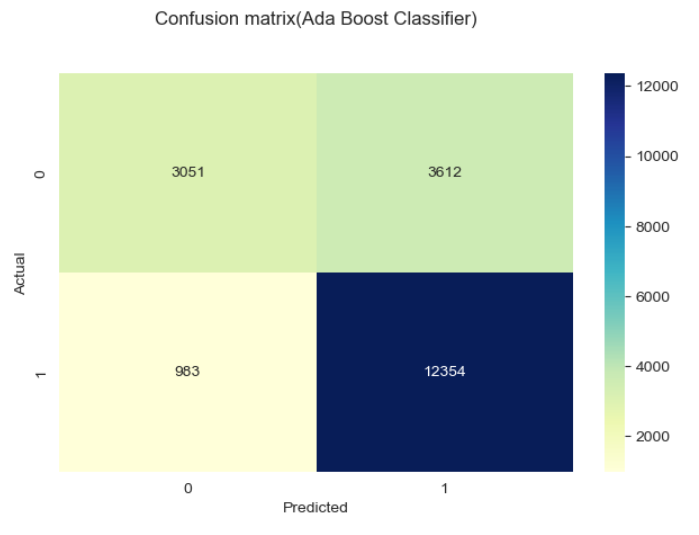
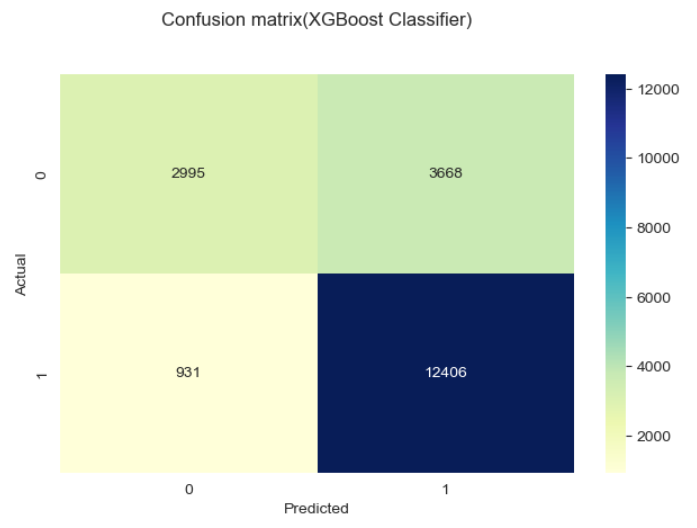
Metode yang digunakan dalam gambar di atas adalah confussion matrix,
Classification matrix (juga dikenal sebagai confusion matrix) adalah tabel yang digunakan untuk mengevaluasi performa model klasifikasi pada dataset uji, di mana nilai aktual dari kelas dan nilai prediksi dari model dibandingkan. Confusion matrix terdiri dari empat sel:
1. True Positive (TP): Jumlah sampel yang sebenarnya positif dan diprediksi positif oleh model.
2. True Negative (TN): Jumlah sampel yang sebenarnya negatif dan diprediksi negatif oleh model.
3. False Positive (FP): Jumlah sampel yang sebenarnya negatif tetapi salah diprediksi positif oleh model (disebut juga error Type I).
4. False Negative (FN): Jumlah sampel yang sebenarnya positif tetapi salah diprediksi negatif oleh model (disebut juga error Type II).
Agar memudahkan pemahaman maka dapat dibuat sederhananya sebagai berikut:
1. TP berada di kiri atas ketika Actual bernilai 0 dan Predicted bernilai 0 juga, artinya pada kasus ini baik data asli dan prediksi dari model sama-sama memiliki hasil bahwa pelanggan tidak churn.
2. TN berada di kanan bawah ketika Actual bernilai 1 dan Predicted bernilai 1 juga, artinya pada kasus ini baik data asli dan prediksi dari model sama-sama memiliki hasil bahwa pelanggan churn.
3. FP berada di kanan atas ketika nilai Actual bernilai 0 dan Predicted bernilai 1, artinya pada kasus ini data asli menunjukan bahwa pelanggan tidak churn namun model memprediksinya sebagai churn.
4. FN berada di kiri bawah ketika nilai Actual bernilai 1 dan Predicted bernilai 0, artinya pada kasus ini data asli menunjukan bahwa pelanggan churn namun model memprediksinya sebagai tidak churn.
6. Evaluation Model
Model yang telah di uji coba selanjutnya dilakukan evaluasi untuk menilai seberapa akurat model. Keakurasian model dapat diukur melalui Akurasi, presisi, recall, dan F1-score. Metrik ini merupakan metrik evaluasi yang digunakan untuk mengukur performa model klasifikasi. Berikut adalah perbandingan masing-masing metrik yang dihasilkan setiap model.
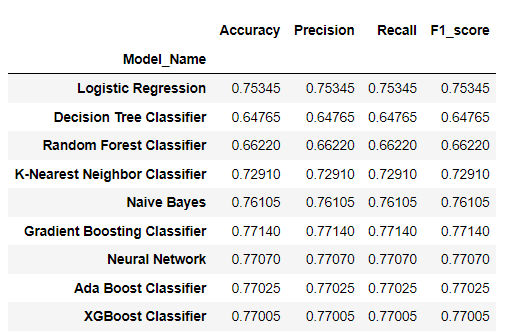
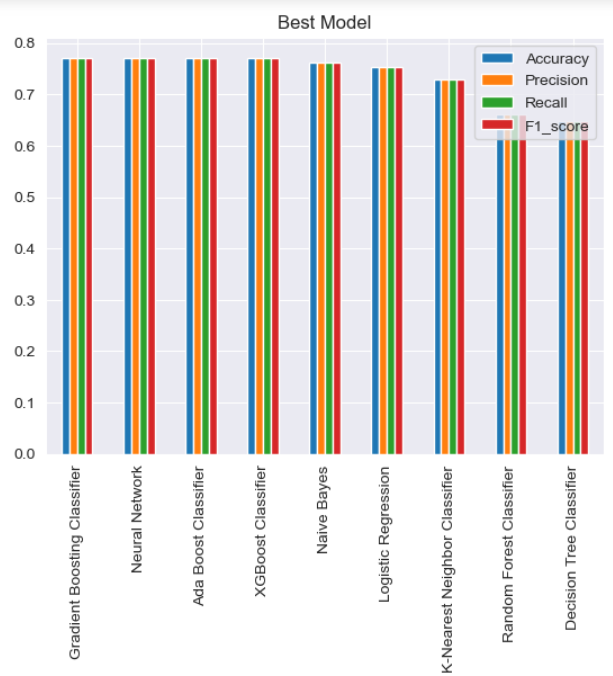
Terlihat ada 3 model dengan metrik terbaik untuk kasus ini yaitu Gradient Boosting Classifier, Neural Network dan Ada Boost Classifier. Hal ini mengindikasikan bahwa model-model ini memiliki keakurasian yang tinggi dalam memprediksi pelanggan churn dibandingkan beberapa model lainnya.
7. Conclusion
Dari hasil analisa dan uji coba model yang telah dilakukan dapat disimpulkan bahwa ada 3 model terbaik yang dapat digunakan dalam memprediksi pelanggan churn dalam kasus ini. Model-model itu adalah Gradient Boosting Classifier, Neural Network dan Ada Boost Classifier, karena ketiga model ini memiliki keakurasian yang lebih tinggi dibandingkan dengan model yang lainnya, maka pada kasus ini diharapkan model-model ini dapat memprediksi dengan lebih baik pelanggan churn pada toko DQLab sport center.
Terima kasih telah meluangkan waktu anda untuk membaca hasil analisa dan uji coba model yang telah dilakukan, silahkan share jika ini dirasa memberikan insight. Tentunya juga diperboleh memberikan masukan melalui kolom komentar atau menghubungi langsung saya dengan kontak di bawah.
Data Source : https://dqlab.id/
Tools : Tableau, Python version : 3.11.3 with package (pandas, matplotlib,seaborn, scikit-learn)
Code Source : https://github.com/MuhZainur/Churn_Prediciton_For_Business_Decision/blob/main/Data_Science_Project_Churn_Prediction_For_Business_Decision.ipynb
LinkedIN : https://www.linkedin.com/in/muhammad-zainurrahman/













