
“Tahukah Anda bahwa di balik angka dan statistik yang tampak biasa pada kumpulan data mobil, tersimpan cerita menarik tentang preferensi konsumen, tren pasar, dan inovasi industri? Sebagai seorang data analyst, tugas kita adalah menggali lebih dalam ke dalam data ini, membongkar pola tersembunyi, dan menghasilkan wawasan berharga yang dapat membimbing keputusan bisnis yang cerdas dan efektif. Mari kita telaah bersama analisis mendalam pada ‘kumpulan data mobil’ ini untuk mengungkap rahasia yang ada di balik roda industri otomotif.”
Pada tahap ini akan dibagi menjadi beberapa poin untuk memudahkan dalam analisis data:
1. Case & Problem Understanding
2. Data Inspect
3. Data Cleaning
4. EDA (Exploratory Data Analysis) & Insight Interpretation
5. Conclusion
Setelah mendapatkan gambaran dari kasus ini, mari kita mulai menyelam lebih jauh tentang data ini di mulai dari : Case & Problem Understanding
1. Case & Problem Understanding
1.1 Overview dataset
Data yang akan dianalisis adalah data yang berasal dari 1985 Ward’s Automotive Yearbook. Data ini merupakan gabungan dari 3 data yang berbeda dengan sumber sebagai berikut:
1) 1985 Model Import Car and Truck Specifications, 1985 Ward’s Automotive Yearbook.
2) Personal Auto Manuals, Insurance Services Office, 160 Water Street, New York, NY 10038
3) Insurance Collision Report, Insurance Institute for Highway Safety, Watergate 600, Washington, DC 20037
Dataset terdiri dari 3 hal utama yaitu spesifikasi dari berbagai jenis karakteristik mobil, rating resiko asuransi dan kerugian yang dialami pengguna dibanginkan dengan mobil lain yang telah dinormalisasi.
1.2 Business Problem
Dalam kasus ini diberikan beberapa problem yang diminta, problem dibuat berdasarkan pelatihan yang diadakan oleh G2Academy yang bekerja sama dengan Prakerja.
- Inspeksi data
- Jenis mobil terbanyak di dataset
- Jenis bbm terbanyak
- Menampilkan 5 jenis mobil dengan horsepower terbesar
- Daftar mobil dengan bahan bakar GAS dan bertipe ‘sedan’
2. Data Inspect
Pada tahap ini akan dilihat lebih detail mengenai data, adapun beberapa langkah dalam Data Inspect adalah sebagai berikut:
1. Import file dari csv
2. Melakukan pengecekan tipe data dan ukuran data
3. Cek nilai statistik yang dimiliki oleh masing-masing data
4. Cek data yang kosong (missing values)
2.1 Import file dari csv
Hal yang paling pertama di lakukan adalah mengimport data, data yang diimport berupa file csv yang akan di definisikan sebagai df nantinya. Setelah mengimport data, maka dilakukan pengecekan 5 data teratas untuk mendapatkan insight sekilas dari data sebagai berikut.
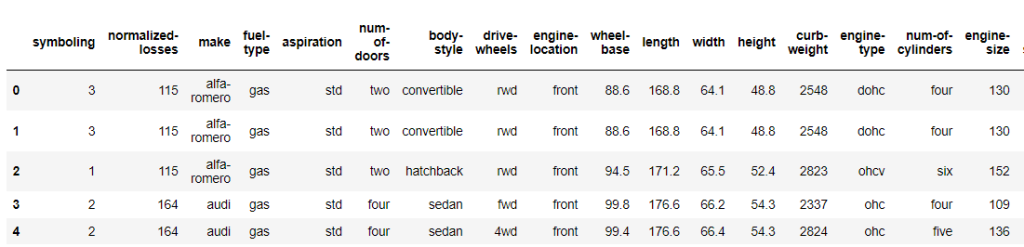
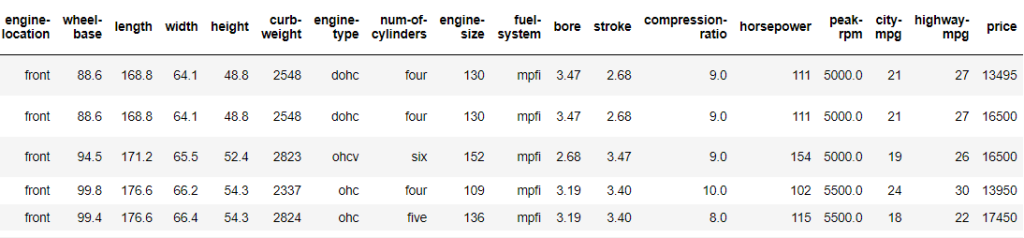
2.2 Melakukan pengecekan tipe data dan ukuran data
Pada tahap selanjutnya adalah melakukan pengecekan tipe data, dalam analisis data tipe data harus diperhatikan sebab jika salah menggunakan tipe data maka akan sulit untuk dilakukan proses analisa, apalagi softwere di desain untuk melakukan analisis dan visual berdasarkan tipe data. Pada pengecekan data di dapat hasil sebagai berikut.
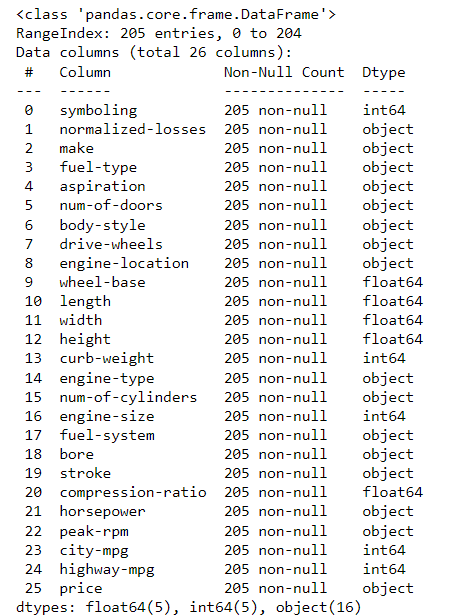
Dari pengecekan, didapatkan bahwa data terdiri dari 205 baris dan 26 kolom, dengan masing-masing ada 16 data bertipe object atau teks, 5 data bertipe float atau desimal dan 5 data bertipe integer atau bilangan bulat. Terlihat pula ada beberapa kolom data yang tidak sesuai dengan tipenya, hal ini nantinya akan diperbaiki pada saat proses data cleaning.
2.3. Cek nilai statistik
Perlu dilakukan pengecekan statistik deskriptif, hal ini mempunyai fungsi untuk nantinya menangani nilai-nilai yang kosong atau memiliki outliers. Berikut adalah masing-masing nilai statistik deskriptif masing-masing kolom.

2.4 Pengecekan missing values dan outliers
Hal pertama yang dilakukan adalah mengecek sebarapa banyak dan tersebar data yang kosong, data yang berhasil terdeteksi adalah sebagai berikut:
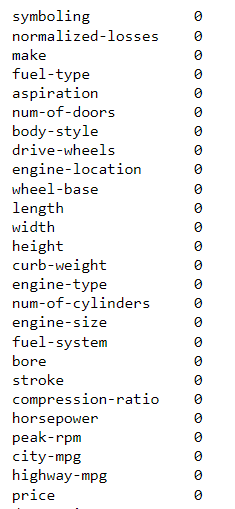
Terlihat tidak ada data kosong, namun ada hal yang perlu diwaspadai. Umumnya dengan menggunakan softwere seperti python, sql, spereadsheet dan softwere lainnya, missing values akan terhitung jika kolom benar-benar memiliki data yang kosong atau tidak digantikan dengan karakter lain seperti ‘?’, ‘kosong’, karakter kosong ‘ ‘, dan lain sebagainya. Namun pada kasus ini data kosong diisi dengan ‘?’ sehingga setelah dilakukan pengecekan ulang maka di dapat jumlah kolom yang memiliki missing values sebagai berikut.
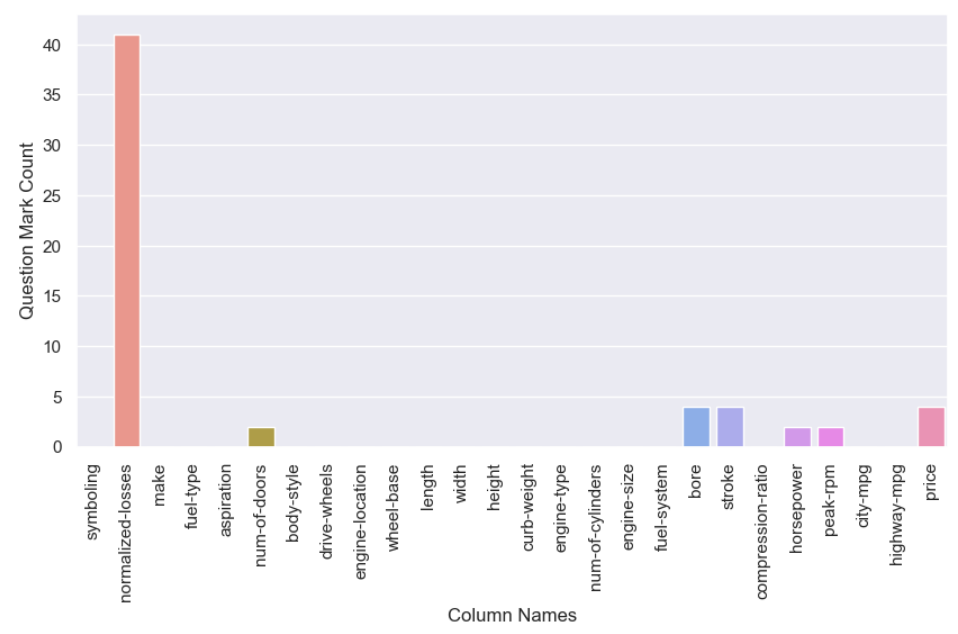
Terlihat ada beberapa kolom yang kosong seperti yang terlihat pada gambar, seperti kolom ‘normalized-losses,’ num-of-doors, ‘bore’, ‘stroke’,’horsepower’,’peak-rpm’,’price’. Selanjutnya dilakukan pengecekan distribusi pada kolom-kolom yang dicurigai memiliki outliers.
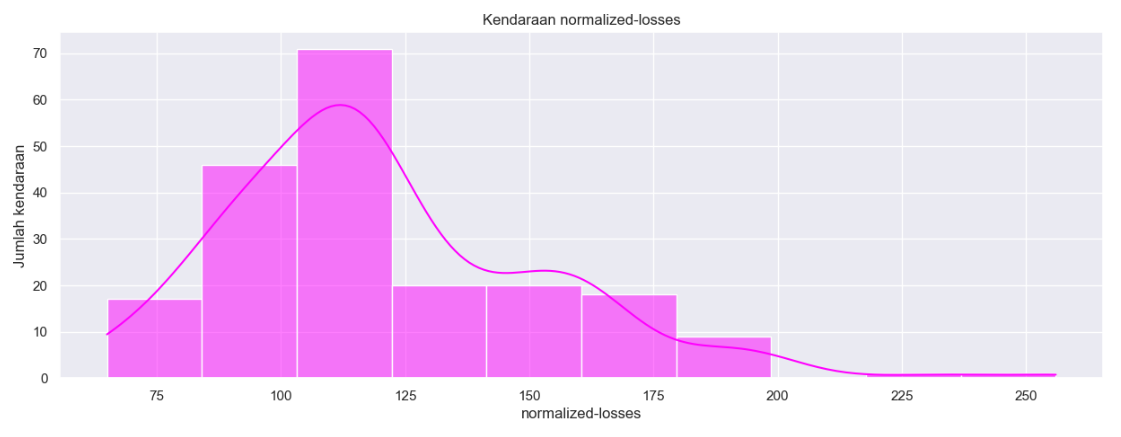
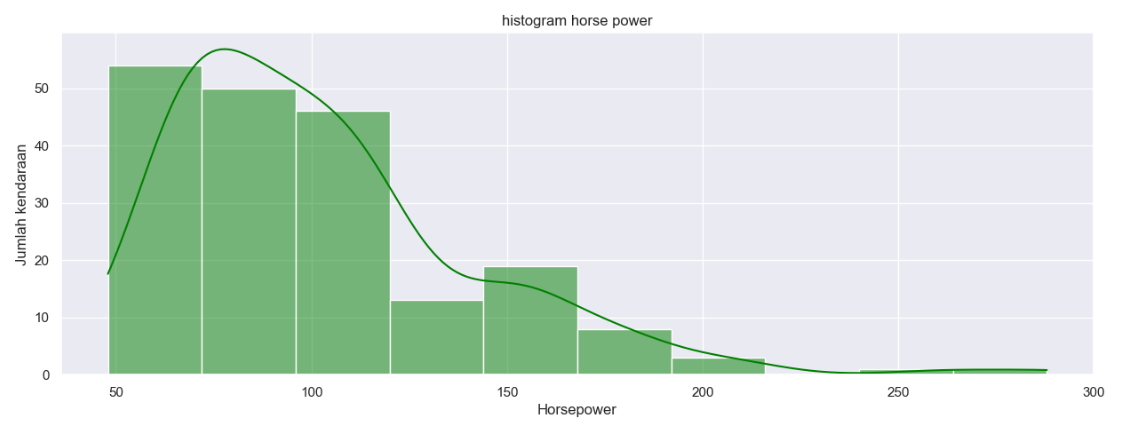
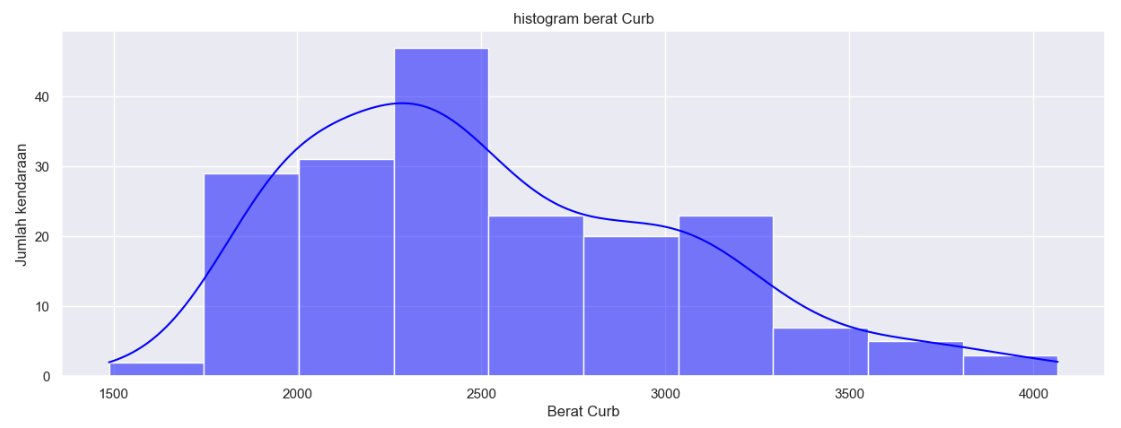
Dari 4 histogram di atas terlihat ‘normalized-losses’ dan ‘horsepower‘ memiliki bentuk persebaran yang tidak merata. Untuk memastikan diperlukan boxplot agar outliers dapat dicek sebagai berikut.
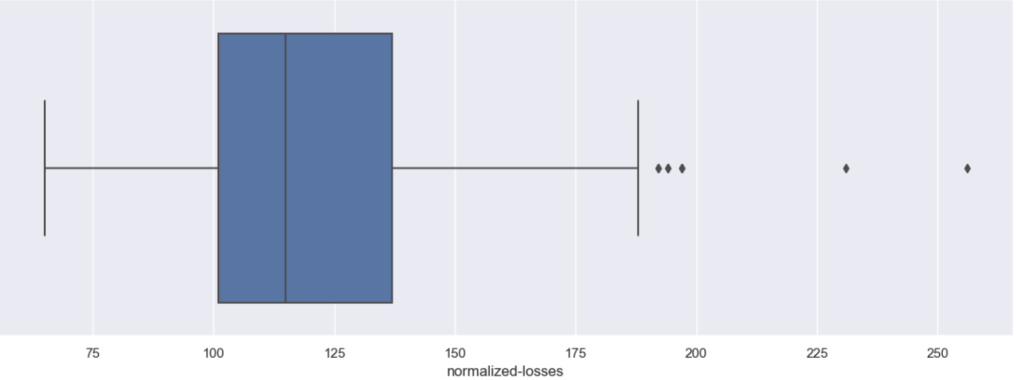
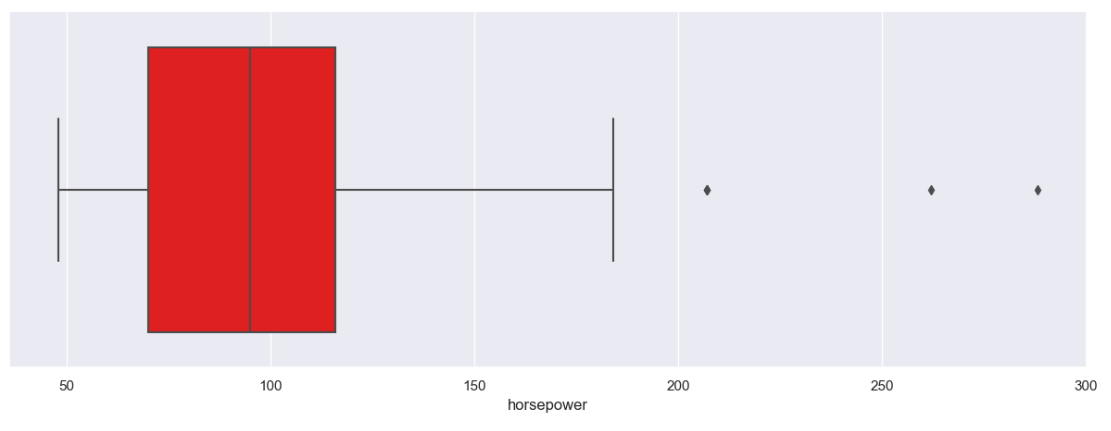
Dari kedua kolom yang dicurigai, ternyata memang benar mengandung outliers hal ini diindikasikan dengan diamond yang berada di luar garis dan kotak pada boxplot. Outliers tidak bisa dibiarkan karena akan mempengaruhi hasil analisa dan pembuatan model machine learning, adapaun salah satu cara yang akan digunakan untuk mengatasi hal ini adalah dengan menggunakan metode IQR (Interquartile Range).
3. Data Cleaning
Pada tahap data cleaning data-data yang tidak sesuai akan diatasi, hal ini bertujuan agar proses yang dianalisis menjadi lebih akurat. Pada tahap sebelumnya telah ditemukan data-data yang mengandung missing values dan outliers. Pada tahap ini akan digunakan metode-metode tertentu untuk mengatasi masalah tersebut, di mulai dari missing values.
Missing values sebelumnya diketahui berada pada kolom normalized-losses,’ num-of-doors, ‘bore’, ‘stroke’,’horsepower’,’peak-rpm’,’price’. Karena beberapa data tidak terdistirbusi normal maka diperlukan median untuk mengisi nilai tersebut, selanjutnya nilai median masing-masing kolom akan digunakan sebagai value yang akan mengisi missing value, hasilnya seperti berikut.
Terlihat tidak ada lagi missing values seperti sebelumnya, pada tahap ini kolom-kolom yang datanya masih bertipe teks juga telah dirubah menjadi lebih sesuai. Langkah selanjutnya adalah mengatasi outliers, berikut adalah metode yang digunakan. Metode IQR (Interquartile Range) adalah salah satu metode statistik yang digunakan untuk mengatasi outlier dalam data. IQR mengukur sebaran data dengan menghitung selisih antara kuartil atas (Q3) dan kuartil bawah (Q1). Kemudian, nilai batas bawah dan batas atas ditentukan dengan menggunakan rumus:
Rumus IQR (Interquartile Range):
[ IQR = Q3 – Q1 ]
Metode Mengatasi Outlier menggunakan IQR:
1. Hitung Nilai Q1 (Kuartil Bawah) dan Q3 (Kuartil Atas).
2. Hitung Nilai IQR menggunakan rumus di atas:
[ IQR = Q3 – Q1 ]
3. Hitung Batas Bawah (Lower Bound):
[Lower Bound = Q1 – 1.5 * IQR ]
4. Hitung Batas Atas (Upper Bound):
[ Upper Bound = Q3 + 1.5 *times IQR ]
5. Identifikasi dan Hapus atau Ubah Nilai yang Kurang dari Batas Bawah atau Lebih dari Batas Atas sebagai Outlier.
Ada dua kolom yang aka menggunakan penanganan ini yaitu ‘normalized-losses’ dan ‘horsepower‘. Berikut hasil boxplot keduanya setelah dilakukan penanganan outliers.
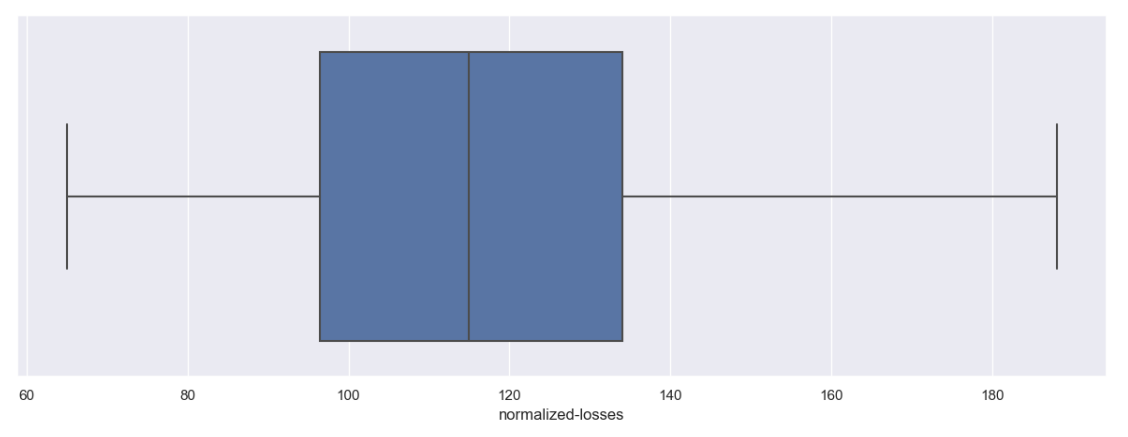
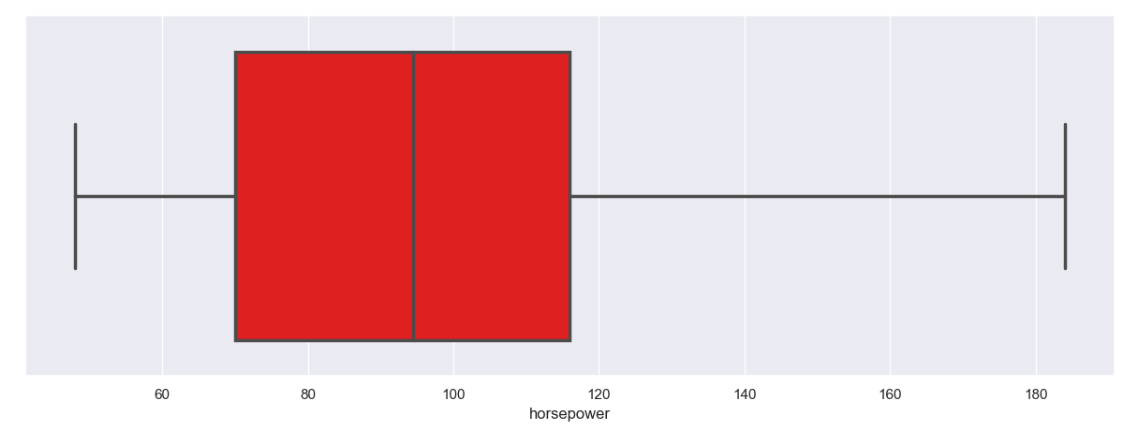
Setelah dilakukan cleaning data maka akan ada perubahan pada nilai statistik deskriptif pada masing-masing kolom. Seperti yang terlihat sekarang terdapat beberapa kolom yang juga terhitung karena telah dikonversi bersamaan dengan proses treatment missing values sehingga beberapa kolom sekarang menjadi integer atau float. Tidak hanya itu bahkan pada gambar berikut beberapa kolom sebelumnya yang mengalami treatment data cleaning juga memiliki perubahan pada nilai statistiknya jika dibandingkan dengan yang sebelumnya.
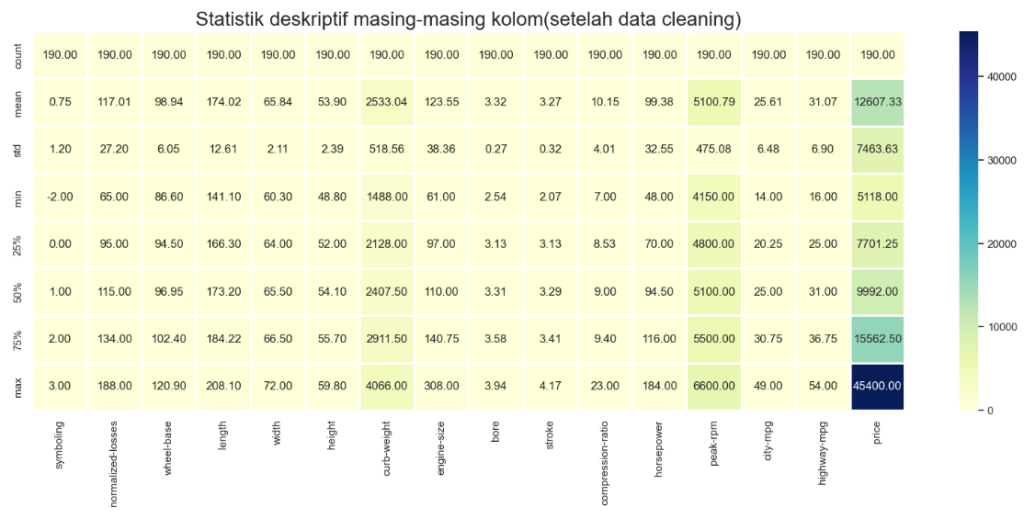
4. EDA (Exploratory Data Analysis) & Insight Interpretation
Setelah dilakukan data cleaning maka data siap diolah, pada tahap EDA berguna agar bisa didapatkan insight dari data. Adapun dari EDA ini nantinya data-data yang telah bersih akan diproses, berikut adalah data-data yang akan diproses dalam tahap EDA.
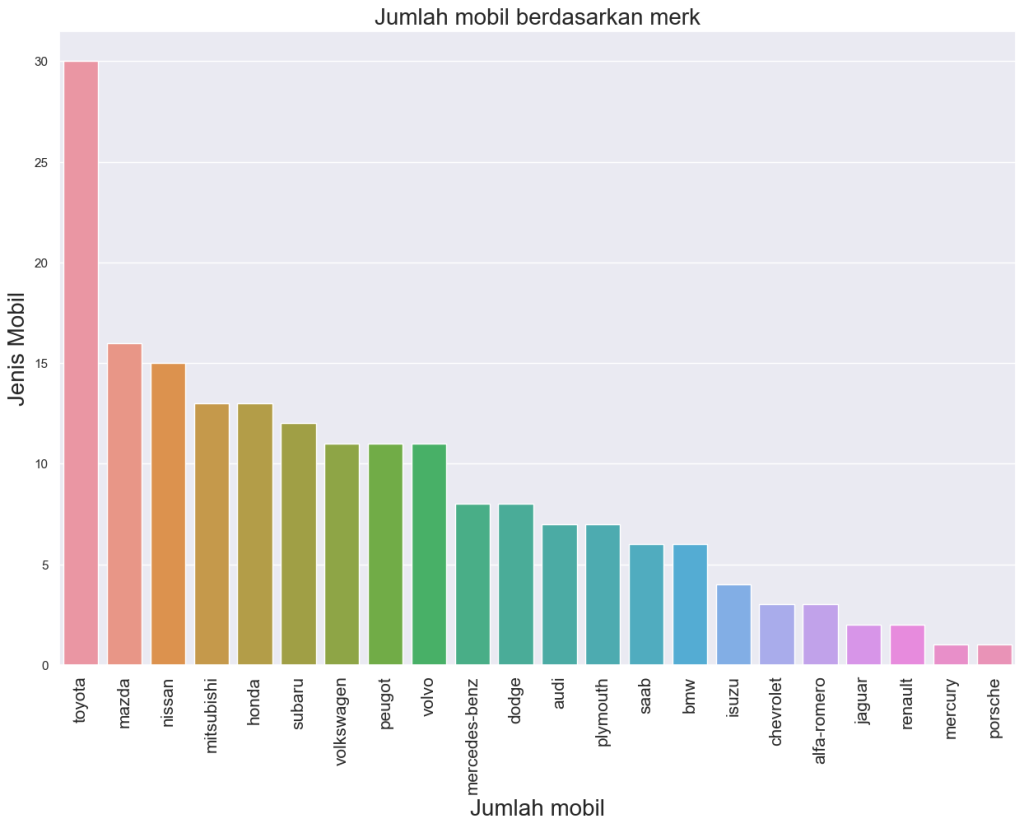
4.1 Jumlah mobil
Berdasarkan grafik tersebut dapat dilihat persebaran jumlah mobil masing-masing merek. Bisa dipastikan bahwa toyota, mazda dan nissan adalah top 3 merek dengan tipe mobil terbanyak dibandingkan dengan merek yang lain.
4.2 Jenis BBM
Terlihat bahwa mayoritas mobil menggunaka BBM dengan jenis gas dibandingkan diesel. Hal ini diindikasikan dengan pengguna gas terdiri dari 90% dibandingkan diesel dengan persentase 10%.
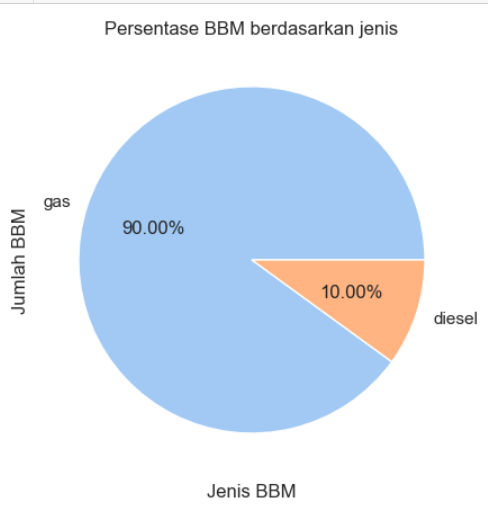
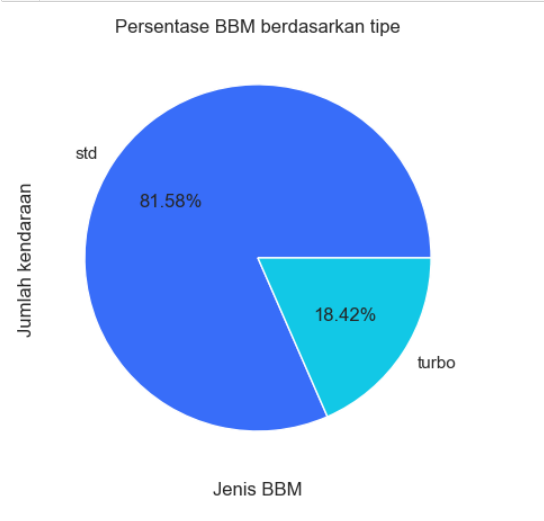
4.3 Tipe BBM
Terlihat juga dari tipe BBM yang digunakan, mayoritas mobil menggunakan tipe standar dengan persentase 81,85% dibandingkan turbo dengan persentase 18,42%.
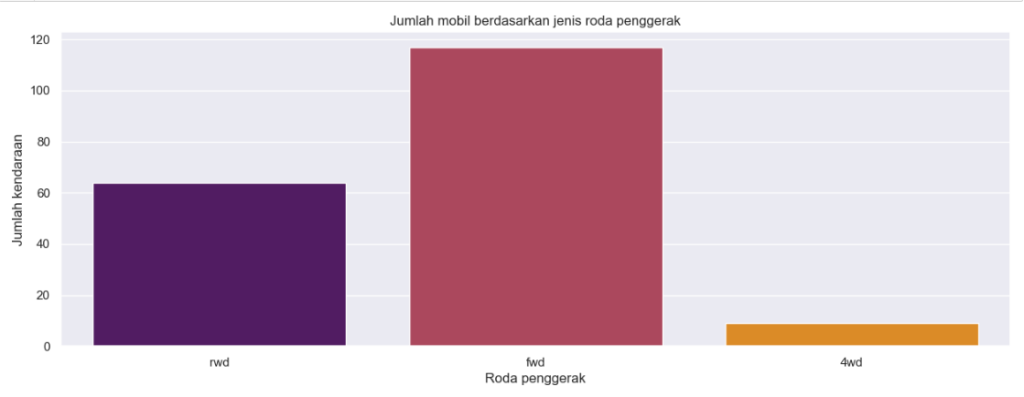
4.4 Roda penggerak
Dapat dilihat mayoritas mobil menggunakan roda penggerak bertipe fwd, diikuti oleh rwd dan terakhir oleh 4wd.
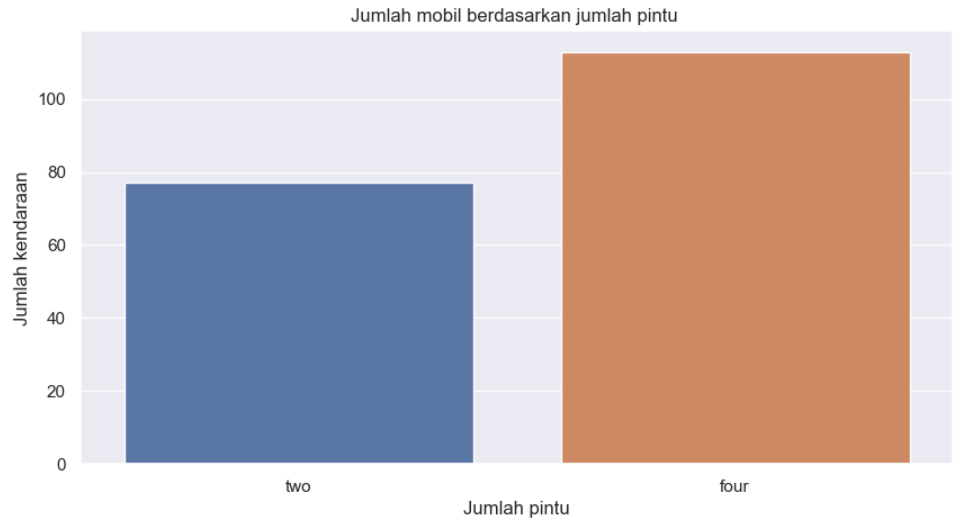
4.5 Jumlah pintu
Mayoritas mobil bertipe 4 pintu, hal ini terlihat dari grafik bahwa mobil dengan 4 pintu lebih banyak dibandingkan dengan mobil bertipe 2 pintu.
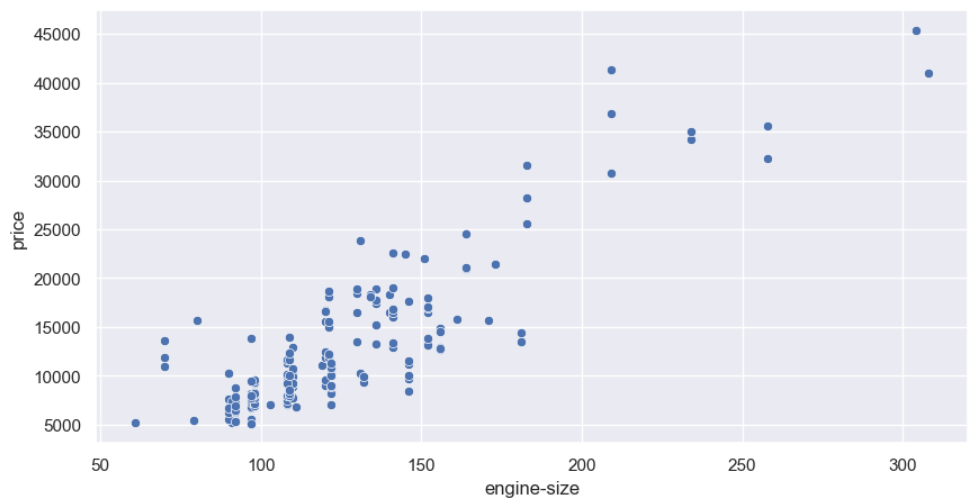
4.6 Korelasi ukuran mesin dan harga
Terdapat korelasi positif antara ukuran mesin dan harga, dapat dilihat dari grafik bahwa semakin besar mesin dari mobil maka akan semakin tinggi juga harganya.
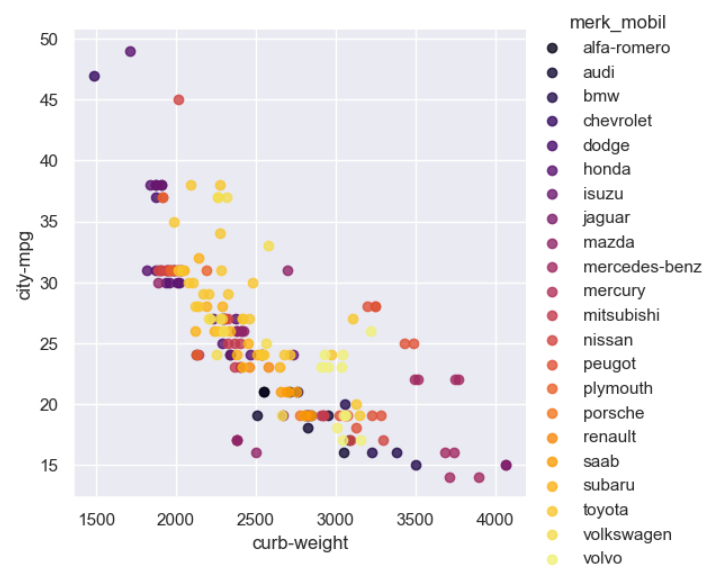
4.7 Korelasi berat kendaraan dan city-mpg berdasarkan merk mobil
Berat mobil memiliki korelasi terhadap city-mpg, city-mpg sendiri memiliki arti sebagai satuan pengukuran efisiensi bahan bakar yang mengukur sejauh mana kendaraan dapat melaju dengan satu galon bahan bakar dalam kondisi berkendara di dalam kota atau daerah perkotaan. Berdasarkan grafik ini keduanya memiliki korelasi negatif artinya semakin berat suatu mobil maka bahan bakar yang digunakan juga akan semakin banyak dengan jarak tempuh yang kecil.
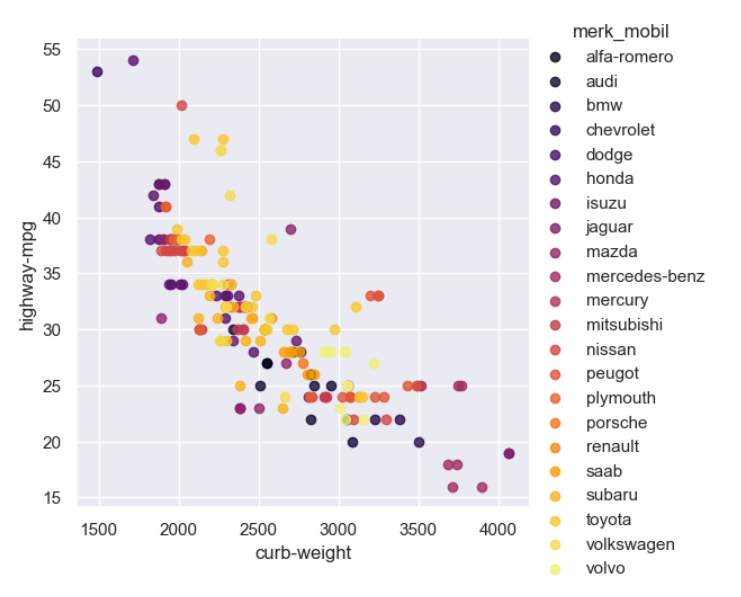
4.8 Korelasi berat kendaraan dan highway-mpg berdasarkan merk mobil
Berat mobil memiliki korelasi terhadap highwat-mpg, highway-mpg sendiri dapat diartikan sebagai satuan pengukuran efisiensi bahan bakar yang digunakan untuk mengukur sejauh mana kendaraan dapat melaju dengan satu galon bahan bakar pada kondisi jalan raya atau jalan tol. Sama seperti city-mpg, semakin berat suatu mobil maka diperlukan bahan bakar yang besar namun dengan jarak tempuh yang kecil, sehingga antara berat mobil dan highway-mpg juga memiliki korelasi negatif.
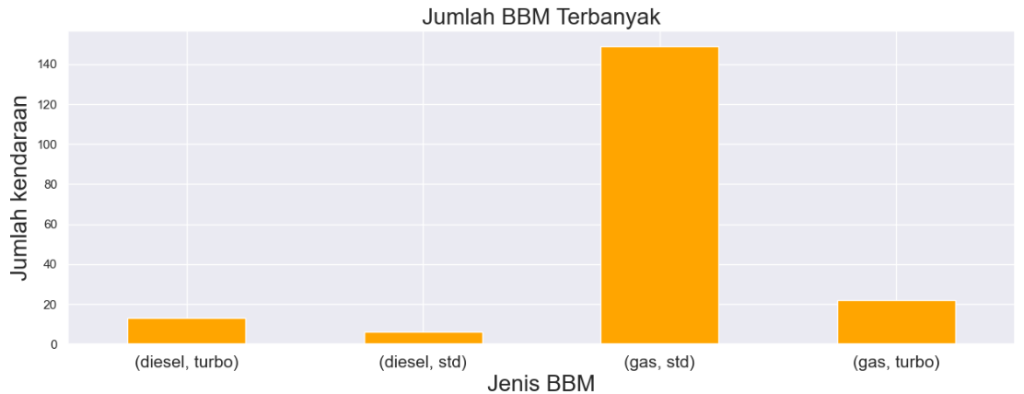
4.9 Jenis dan tipe BBM
Diketahui sebelumnya ada 2 jenis BBM yaitu gas dan diesel, dengan masing-masing terbagi menjadi 2 tipe yaitu standar dan turbo. Berikut adalah perbandingannya, terlihat bahwa mayoritas mobil menggunakan BBM berjenis gas dengan tipe standar, jenis dan tipe ini lebih mendominasi dibandingkan dengan jenis dan tipe yang lainnya.
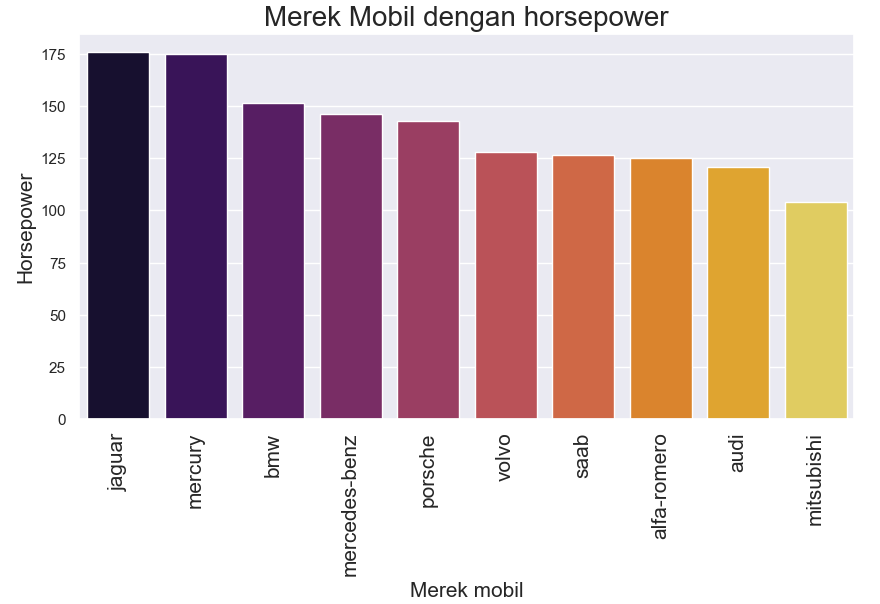
4.10 Merek mobil dengan horsepower terbesar
Setiap mobil memiliki horsepower yang berbeda-beda, berikut 10 mobil dengam horsepower terbesar.
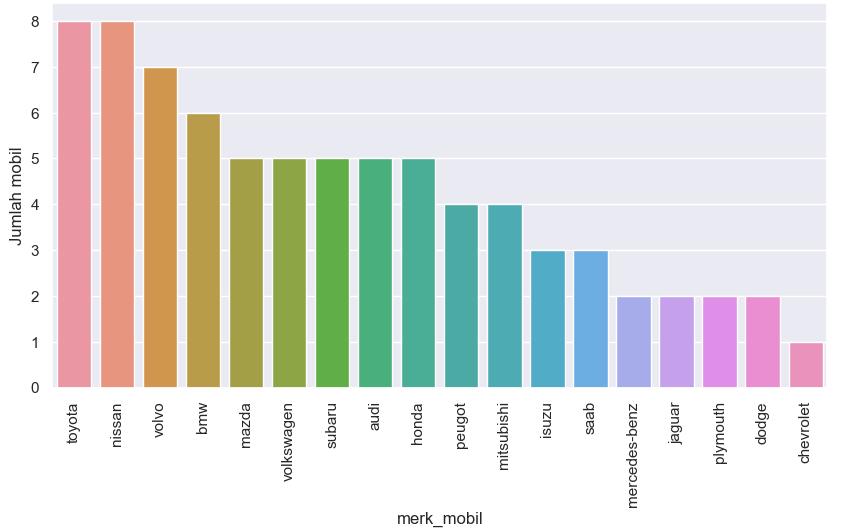
4.11 Mobil berjenis BBM gas dan memiliki body style sedan
Terlihat bahwa toyota, nissan dan volvo adalah top 3 mobil terbanyak yang menggunakan gas sebagai jenis BBMnya serta body style-nya adalah sedan.
5. Conclusion
Berdasarkan analisis yang telah dilakukan didapat kesimpulan dan dapat menjawab pertanyaan dari yang diminta oleh bisnis sebagai berikut:
1. Dari inspeksi data yang telah dilakukan terdapat beberapa variabel yang memiliki korelasi negatif seperti berat mobil-city mpg dan berat mobil-highway mpg, lalu terdapat korelasi positif antara besarnya mesin dan harga. Mayoritas mobil menggunakan roda penggerak dengan jenis fwd dan mayoritas mobil adalah bertipe 4 pintu.
2. Dari 20 jenis mobil terbanyak, ada 3 merk mobil yang berada diposisi 3 besar yaitu Toyota, Mazda dan Nissan.
3. Jenis bbm terbanyak adalah jenis gas dan bertipe standar.
4. 5 Mobil dengan horsepower terbesar adalah Jaguar, Mercury, BMW, Mercedes-Benz dan Porsche.
5. Toyota,Nissan dan Volvo menguasai posisi 3 besar mobil dengan tipe sedan dan berbahan bakar gas.
Hasil dashboard analisis dapat di klik pada gambar berikut.
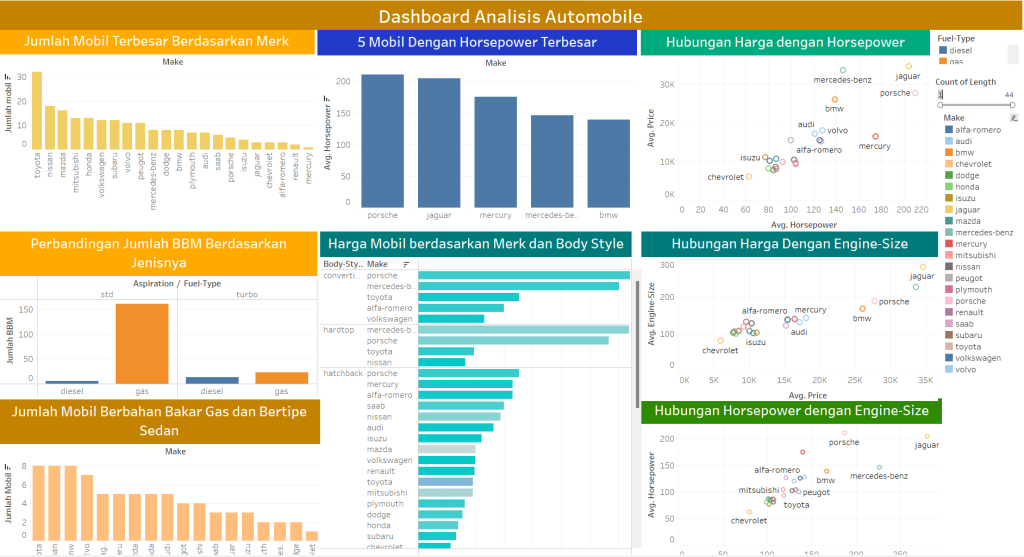
Selanjutnya anda dapat melihat kelanjutan dari postingan ini, di mana akan diprediksi harga mobil berdasarkan data yang ada. Berikut link project terkait : https://jagoketik.com/blog/revolusi-dunia-otomotif-memprediksi-harga-mobil-dengan-machine-learning-data-science-project/
Terima kasih telah meluangkan waktu anda untuk membaca hasil analisa yang telah dilakukan semoga menambah insight anda, silahkan share jika ini dirasa memberikan insight. Tentunya juga diperboleh memberikan masukan melalui kolom komentar atau menghubungi langsung saya dengan kontak di bawah.
Data source : https://www.kaggle.com/datasets/toramky/automobile-dataset
LinkedIN : https://www.linkedin.com/in/muhammad-zainurrahman/
Source code: https://github.com/MuhZainur/Automobile/blob/main/Automobile%20analysis.ipynb
Tools : Python version : 3.11.3, package : pandas, seaborn, numpy, matplotlib.
Saya juga memiliki beberapa sertikasi di bidang data sebagai bukti kelayakan dari kemampuan yang saya miliki sebagai berikut:













